Share this post
사라진 800MB를 찾아서
https://luavis.me/server/missing-800mb메쉬코리아 부릉에서는 라이더분들이 배달을 실행하기 위해서 배달 요청을 잡는 일을 AI가 가장 효율적인 배차가 가능하도록 자동으로 할당해주는 시스템인 “추천배차”라는 시스템이 있습니다. 이 추천배차 시스템에서 사용하는 메모리량이 꾸준히 증가하고 있는 이슈가 생겨서 NewRelic과 sysfs를 이용해서 원인을 파악해보고 누수가 생긴 이유까지 찾은 이야기를 글로 적은 내용입니다.
문제를 찾아가는 과정
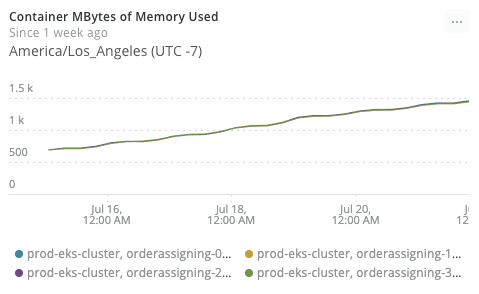 [꾸준히 상승하는 메모리 사용량]
[꾸준히 상승하는 메모리 사용량]
7일만에 메모리가 약 3배 이상으로(대략 600M → 1.4G) 올라가면 문제가 있다고 판단했고 해당 문제의 원인을 파악해보기 위해서 소스코드를 확인해봤지만 별다른 이상한 점은 발견하기 힘들었습니다. 그렇다면 자바 Heap 영역에서 문제/누수가 발생하고 있는것은 아닌지 확인해볼 필요가 있어서 APM에서 나오는 Heap 메모리의 사용량도 확인해보았고, Thread stack 메모리가 사용하는 메모리는 아닐까 의심되어 확인해봤지만 Thread 수에도 큰 문제가 발생하지 않는것을 확인할 수 있었습니다.
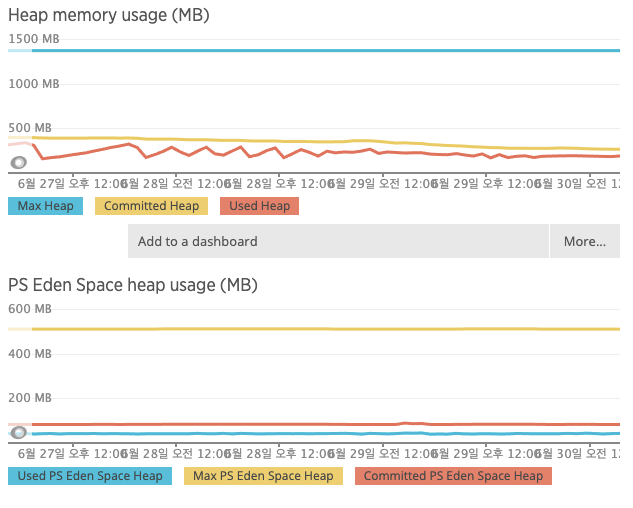 [평화로운 JAVA heap memory]
[평화로운 JAVA heap memory]
문제가 java에 있지 않다면 NewRelic의 수집 방식에 문제가 있거나 혹은 linux 시스템적으로 사용하는 메모리가 증가하고 있을거라 생각이 되어서 k9s를 이용해서 kubernetes가 판단하고 있는 현재 메모리 사용률에 대해서 확인해봤습니다. 확인해본 결과 kubernetes에서 사용하는 판단하는 메모리 사용량은 635MB 정도로 자바가 차지하는 Heap memory를 고려할때 이상이 없는 수치라고 생각이 됩니다. 그러면 문제는 없어진 800M의 메모리는 어디로 간 것인가 입니다. 이 문제를 파악해보기 위해 많은 리서치를 해봤고 하나 알아낸것은 컨테이너를 매니징하는 프로그램(docker와 같은)과 newrelic이 생각하는 메모리와 kubernetes가 생각하는 메모리가 다르다는 것을 확인할 수 있었습니다.
리눅스는 머신이 갖고 있는 메모리를 swap, 캐시, 버퍼 캐시 등등 다양한 방법으로 최대한 많은 메모리를 사용하여 머신의 성능을 끌어올립니다. 따라서 한 process가 memory를 사용한다는 개념이 어떤 부분(RSS, cache, …)들을 사용량으로 볼 것인지 조금씩 다르다는것을 확인할 수 있었습니다.
docker와 NewRelic에서는 RSS와 그외 buffer / cache등 모든 메모리 사용의 총합을 고려해서 판단합니다. 하지만 이와 반대로 k8s에서는 memory 사용량을 kubelet으로 확인하면 물리적 메모리 사용량(RSS)를 가져가는것으로 확인했습니다. 이에 대한 discussion이 이 글에 자세히 나와 있습니다.
The value K8sContainerSample.memoryUsedBytes will pull the usageBytes metric from the /stats/summary endpoint of the kubelet, scoped to the container. As you noted that value included the linux buffers and cache.
따라서 위의 NewRelic 대시보드에 메모리 사용도 application에서 사용하는 실제 메모리가 아닌 시스템 레벨에서 사용되는 메모리에 문제가 있을 것이라 추측할 수 있었습니다. 따라서 추천배차 시스템에서 RSS의 사용량 추세가 수평적인지 선형적인지를 판단해보면 cache외의 메모리또한 증가세인지 확인할 수 있습니다. 이를 위해서는 NewRelic의 Insights를 통해서 NRQL을 사용해 확인해볼 수 있었습니다.
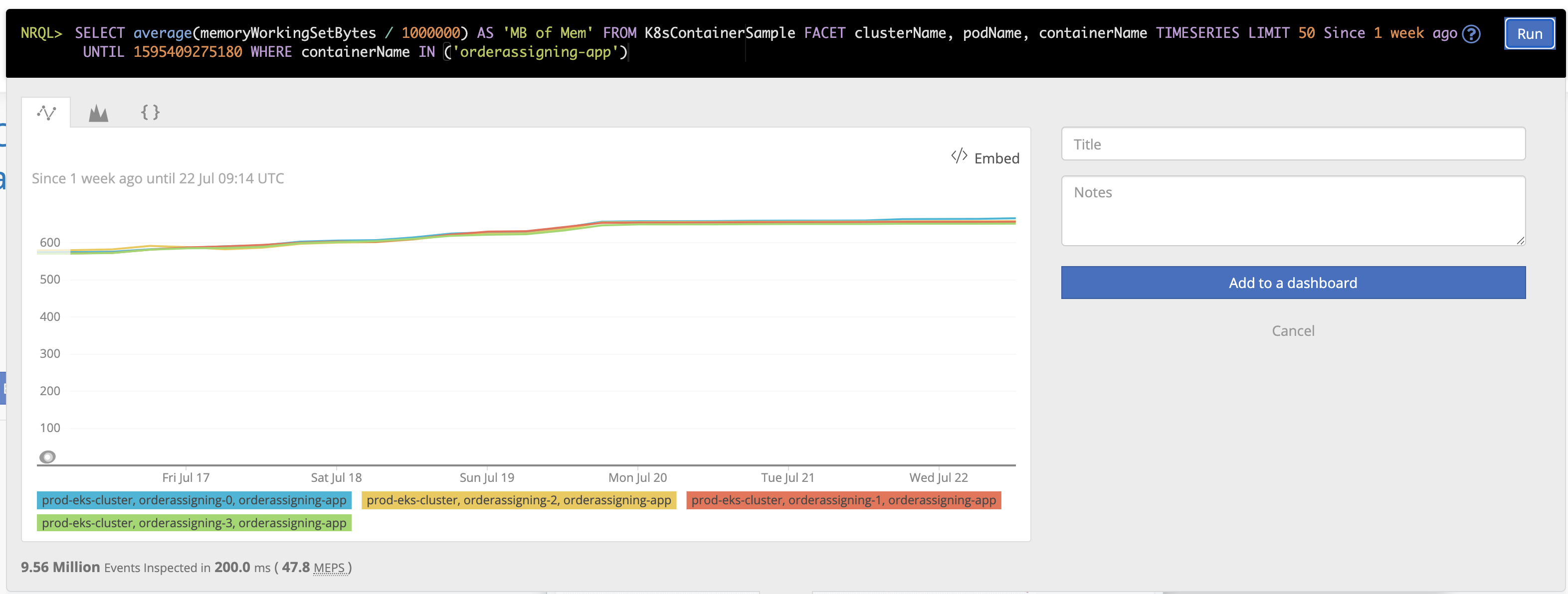 [평화로운 memoryWorkingSetBytes]
[평화로운 memoryWorkingSetBytes]
NRQL> SELECT average(memoryWorkingSetBytes / 1000000) AS ‘MB of Mem’ FROM K8sContainerSample FACET clusterName, podName, containerName TIMESERIES LIMIT 50 Since 1 week ago UNTIL 1595409275180 WHERE containerName IN (‘***’)
NewRelic에서는 RSS를 memoryWorkingSetBytes라는 이름으로 수집하고 있고 이 메모리 사용량만 확인해보면 기간 대비 평탄한 사용량을 갖고 있음을 확인할 수 있었습니다. 그러면 나머지 800M의 메모리는 어떻게 누가 먹고 있는가를 확인해보기 위해서 찾아봤습니다.
실제 컨테이너에 접속하여 확인해봤는데 ps, free 와 같은 커맨드를 사용할 수도 설치할 수도 없어서 확인이 어려웠지만, 이 프로그램들은 procfs를 읽어서 사용하기 때문에 컨테이너의 정보가 아닌 실제 물리머신 node의 성능이 나옵니다. 일례로 container에 접속하여 /proc/meminfo 를 확인하면 약 64기가, 물리 머신의 성능이 나오는 것을 확인할 수 있습니다.
...
MemTotal: 65150604 kB
MemFree: 41145196 kB
MemAvailable: 49117724 kB
Buffers: 2088 kB
Cached: 7098816 kB
...
따라서 현재 컨테이너를 확인해보고 싶다면 다른 방법을 찾아봐야합니다.
리눅스에서는 container라는 추상적인 개념을 cgroup를 이용해 구현했기 때문에 이 정보를 커널로부터 얻어올 수 있는 곳은 sysfs입니다. /sys/fs/cgroup에는 현재 cgroup에 관한 정보를 조회할 수 있습니다. 이 밑에 memory에는 다양한 메모리 지표를 뽑아서 확인할 수 있는 파일들이 있습니다. 가장 human readable한 정보가 나오는 곳은 /sys/fs/cgroup/memory/memory.stat 파일입니다.
$ cat /sys/fs/cgroup/memory/memory.stat
cache 822972416
rss 652750848
rss_huge 0
shmem 0
mapped_file 86016
...
확인해보면 cache memory가 822972416 B로 찾아다녔던 그 800M의 메모리인것을 확인할 수 있습니다.
그러면 memory.stat에서 말하는 cache라는 지표가 어떤 값을 의미하는지 확인해볼 필요가 있기 때문에 검색해 봤고
리눅스 커널 docs의 cgroup memory에 5.2 section에
아주 잘 설명되어 있습니다.
cache - # of bytes of page cache memory.
rss - # of bytes of anonymous and swap cache memory (includes
transparent hugepages).
rss_huge - # of bytes of anonymous transparent hugepages.
mapped_file - # of bytes of mapped file (includes tmpfs/shmem)
pgpgin - # of charging events to the memory cgroup. The charging
event happens each time a page is accounted as either mapped
anon page(RSS) or cache page(Page Cache) to the cgroup.
...
커널 documentation에서는 cache를 page cache memory 바이트 수라고 이야기하고 있습니다. page cache는 Block device I/O 시에 리눅스가 성능의 최적화를 위해서 사용하는 메모리로 파일 내용을 임시적으로 저장해두는 장소입니다. 자세한 설명
결론: 없어진 800M 은 페이지 캐시였다.
문제의 근본 원인을 찾아서
여기까지 왔을때는 아 그냥 캐시가 많이 쌓이네 뭐 상관 없지 않을까? 라고 생각했지만 다른 서비스는 전혀 이런 문제가 생기지 않는데 추천배차에서만 생긴다는것도 이상했고 무엇보다 file I/O 작업이 없는 서비스인데 이렇게 많은 캐시가 쌓이는 것도 이상하다는 생각이 들어서 조금 더 drill down 해보기로 했습니다.
혹여나 놓쳐진 부분이 있지 않을까 싶어서 procfs를 찾아서 열려있는 fd(file descriptor)를 확인해봤습니다. /proc/1/fd를 리스팅하면 모든 fd number와 해당하는 파일에 대해서 열람할 수 있습니다.
...
lr-x------ 1 jhipster jhipster 64 Jul 21 10:02 28 -> /home/jhipster/app.war
lr-x------ 1 jhipster jhipster 64 Jul 21 10:02 28 -> /usr/local/openjdk-8/lib/charsets.jar
lrwx------ 1 jhipster jhipster 64 Jul 21 10:02 26 -> socket:[859629097
l-wx------ 1 jhipster jhipster 64 Jul 21 10:02 27 -> /tmp/spring.log
lr-x------ 1 jhipster jhipster 64 Jul 21 10:02 28 -> /tmp/instrumentation7299792729183652257.jar
...
fd에는 다양한 파일들이 있지만 jar, war 파일을 제외하면 Block I/O가 발생할 수 있는 파일은 27번 /tmp/spring.log 파일이 가장 유력해보였습니다.
$ du -h
32K ./hsperfdata_jhipster
0 ./hsperfdata_root
794M .
800M가 없어진 원인을 찾았습니다. /tmp에 파일을 썼을때 쓴 만큼 cache 메모리에 쌓이는지 실험해봤고 비슷한 정도로 쌓이는 것을 확인할 수 있었습니다. 다른 애플리케이션과 대비해서 추천배차에서 문제가 있었던것은 log의 level이 잘못 설정되어 있어서 많은 로그가 쌓이게 되었고 이 로그가 컨테이너 안에 파일형태로 남게 되면서 쓰는 과정에 cache로 남아있는것을 확인할 수 있었습니다.
container는 로그를 포함함 쓰기 작업을 컨테이너 내에서 하는것을 비권장합니다. stateless하지도 않고 위와 같은문제가 발생할 수 있습니다. 특히나 로그는 docker logs와 같이 container manager의 로그 시스템과 연결되지 않는다면 로그 수집 과 관리가 어려움으로 이런 부분은 특히나 조심해야합니다. spring에서는 이 문제를 log appender의 설정을 변경하여 해결할 수 있습니다.